

Exploring Fitbit Data Using FitBit's API
Google Data Analytics Specialization Capstone Project
Bellabeat is a high-tech manufacturer of health-focused products for women. As a junior data analyst working with marketing analyst team at Bellabeat, a high-tech manufacturer of health-focused products for women. Bellabeat is a successful small company, but they have the potential to become a larger player in the global smart device market. Urška Sršen, cofounder and Chief Creative Officer of Bellabeat, believes that analyzing smart device fitness data could help unlock new growth opportunities for the company. I have been asked to focus on one of Bellabeat’s products and analyze smart device data to gain insight into how consumers are using their smart devices. Urška Sršen is confident that an analysis of non-Bellebeat consumer data (ie. FitBit fitness tracker usage data) would reveal more opportunities for growth. The insights from the data will help to guide marketing strategy for the company. I have performed analysis on data along with high level recommendations for Bellabeat’s marketing strategy.
Business Task: Analyze FitBit fitness tracker data to gain insights into how consumers are using the FitBit app and discover trends for Bellabeat marketing strategy.
01
Ask Phase
Firstly, we need to address who are our key stakeholders? In this case, we have following stakeholders:
-
Urška Sršen: Bellabeat’s co-founder and Chief Creative Officer
-
Sando Mur: Mathematician and Bellabeat’s co-founder; key member of the Bellabeat executive team
-
Bellabeat marketing analytics team: A team of data analysts responsible for collecting, analyzing, and reporting data that helps guide Bellabeat’s marketing strategy.
Business Objectives:
-
What are some trends in smart device usage?
-
How could these trends apply to Bellabeat customers?
-
How could these trends help influence Bellabeat marketing strategy?
02
Prepare Phase
Sršen encouraged me to use public data that explores smart device users’ daily habits. She points me to a specific data set:
-
FitBit Fitness Tracker Data (CC0: Public Domain, dataset made available through Mobius): This Kaggle data set contains personal fitness tracker from thirty fitbit users. Thirty eligible Fitbit users consented to the submission of personal tracker data, including minute-level output for physical activity, heart rate, and sleep monitoring. It includes information about daily activity, steps, and heart rate that can be used to explore users’ habits. Data is publicly available on Kaggle: FitBit Fitness Tracker Data and stored in 18 csv files.
In the Prepare phase, we identify the data being used and its limitations:
-
Data is collected 7 years ago in 2016. Users’ daily activity, fitness and sleeping habits, diet and food consumption may have changed since then. Data may not be timely or relevant.
-
Sample size of 30 FitBit users is not representative of the entire fitness population.
-
As data is collected in a survey, So we can not be assure about its integrity or accuracy.
Is the data ROCCC?
A good data source is ROCCC which stands for Reliable, Original, Comprehensive, Current, and Cited.
-
Reliable — LOW — Not reliable as it only has 30 respondents
-
Original — LOW — Third party provider (Amazon Mechanical Turk)
-
Comprehensive — MED — Parameters match most of Bellabeat products’ parameters
-
Current — LOW — Data is 7 years old and may not be relevant
-
Cited — LOW — Data collected from third party, hence unknown Overall, the dataset is considered bad quality data and it is not recommended to produce business recommendations based on this data
I have downloaded the data from secure browser in my secured hard disk. And stored under a secured folder inside the file.
03
Process Phase
In this phase we will process the data by cleaning and ensuring that it is correct, relevant, complete and error free.
-
We have to check if data contains any missing or null values
-
Transform the data into format we want for the analysis
Tool:
I have used RStudio for data cleaning, data transformation, data analysis and visualization.
Firstly, we need to install and read the packages we need for analysis: I have all packages installed, so I read all the packages simultaneously.
install.packages("skimr")
install.packages("lubridate")
install.packages("sqldf")
install.packages("janitor")
install.packages("plotrix")
install.packages("tidyverse")
library(sqldf) #For using SQL queries
library(skimr) #For summarizing data
library(dyplr) #For data manipulation
library(ggplot2) #For data visualization
## -- Attaching packages ---------------------------------------- tidyverse 1.3.1 ----
## v ggplot2 3.3.5 v purrr 0.3.4
## v tibble 3.1.6 v dplyr 1.0.7
## v tidyr 1.2.0 v stringr 1.4.0
## v readr 2.1.2 v forcats 0.5.1
## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()
## Loading required package: gsubfn
## Loading required package: proto
## Loading required package: RSQLite
## Attaching package: 'janitor'
## The following objects are masked from 'package:stats':
##
## chisq.test, fisher.test
We can read the data stored from secured hard disk with help of command read.csv and store them in a variable of our choice.
library(readr)
daily_activity <- read_csv("Desktop/fitbit_data_2016/dailyActivity_merged.csv")
View(daily_activity)
library(readr)
daily_sleep <- read_csv("Desktop/fitbit_data_2016/sleepDay_merged.csv")
View(daily_sleep)
library(readr)
weight_log <- read_csv("Desktop/fitbit_data_2016/weightLogInfo_merged.csv")
View(weight_log)
Next, we need to check for any nulls or missing values in each data. We'll use the following commands to check.
str(daily_activity)
spec_tbl_df [940 × 18] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ Id : num [1:940] 1.5e+09 1.5e+09 1.5e+09 1.5e+09 1.5e+09 ...
$ ActivityDate : chr [1:940] "4/12/2016" "4/13/2016" "4/14/2016" "4/15/2016" ...
$ TotalSteps : num [1:940] 13162 10735 10460 9762 12669 ...
$ TotalDistance : num [1:940] 8.5 6.97 6.74 6.28 8.16 ...
$ TrackerDistance : num [1:940] 8.5 6.97 6.74 6.28 8.16 ...
$ LoggedActivitiesDistance: num [1:940] 0 0 0 0 0 0 0 0 0 0 ...
$ VeryActiveDistance : num [1:940] 1.88 1.57 2.44 2.14 2.71 ...
$ ModeratelyActiveDistance: num [1:940] 0.55 0.69 0.4 1.26 0.41 ...
$ LightActiveDistance : num [1:940] 6.06 4.71 3.91 2.83 5.04 ...
$ SedentaryActiveDistance : num [1:940] 0 0 0 0 0 0 0 0 0 0 ...
$ VeryActiveMinutes : num [1:940] 25 21 30 29 36 38 42 50 28 19 ...
$ FairlyActiveMinutes : num [1:940] 13 19 11 34 10 20 16 31 12 8 ...
$ LightlyActiveMinutes : num [1:940] 328 217 181 209 221 164 233 264 205 211 ...
$ SedentaryMinutes : num [1:940] 728 776 1218 726 773 ...
$ Calories : num [1:940] 1985 1797 1776 1745 1863 ...
skim(daily_activity)
skim_variable n_missing complete_rate mean sd p0 p25 p50 1 Id 0 1 4.86e+9 2.42e+9 1503960366 2320127002 4.45e+9 2 TotalSteps 0 1 7.64e+3 5.09e+3 0 3790. 7.41e+3 3 TotalDistance 0 1 5.49e+0 3.92e+0 0 2.62 5.24e+0 4 TrackerDistance 0 1 5.48e+0 3.91e+0 0 2.62 5.24e+0 5 LoggedActivitiesDistance 0 1 1.08e-1 6.20e-1 0 0 0 6 VeryActiveDistance 0 1 1.50e+0 2.66e+0 0 0 2.10e-1 7 ModeratelyActiveDistance 0 1 5.68e-1 8.84e-1 0 0 2.40e-1 8 LightActiveDistance 0 1 3.34e+0 2.04e+0 0 1.95 3.36e+0 9 SedentaryActiveDistance 0 1 1.61e-3 7.35e-3 0 0 0 10 VeryActiveMinutes 0 1 2.12e+1 3.28e+1 0 0 4 e+0 11 FairlyActiveMinutes 0 1 1.36e+1 2.00e+1 0 0 6 e+0 12 LightlyActiveMinutes 0 1 1.93e+2 1.09e+2 0 127 1.99e+2 13 SedentaryMinutes 0 1 9.91e+2 3.01e+2 0 730. 1.06e+3 14 Calories 0 1 2.30e+3 7.18e+2 0 1828. 2.13e+3
head(daily_activity)
spec_tbl_df [940 × 18] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ Id : num [1:940] 1.5e+09 1.5e+09 1.5e+09 1.5e+09 1.5e+09 ...
$ ActivityDate : chr [1:940] "4/12/2016" "4/13/2016" "4/14/2016" "4/15/2016" ...
$ TotalSteps : num [1:940] 13162 10735 10460 9762 12669 ...
$ TotalDistance : num [1:940] 8.5 6.97 6.74 6.28 8.16 ...
$ TrackerDistance : num [1:940] 8.5 6.97 6.74 6.28 8.16 ...
$ LoggedActivitiesDistance: num [1:940] 0 0 0 0 0 0 0 0 0 0 ...
$ VeryActiveDistance : num [1:940] 1.88 1.57 2.44 2.14 2.71 ...
$ ModeratelyActiveDistance: num [1:940] 0.55 0.69 0.4 1.26 0.41 ...
$ LightActiveDistance : num [1:940] 6.06 4.71 3.91 2.83 5.04 ...
$ SedentaryActiveDistance : num [1:940] 0 0 0 0 0 0 0 0 0 0 ...
$ VeryActiveMinutes : num [1:940] 25 21 30 29 36 38 42 50 28 19 ...
$ FairlyActiveMinutes : num [1:940] 13 19 11 34 10 20 16 31 12 8 ...
$ LightlyActiveMinutes : num [1:940] 328 217 181 209 221 164 233 264 205 211 ...
$ SedentaryMinutes : num [1:940] 728 776 1218 726 773 ...
$ Calories : num [1:940] 1985 1797 1776 1745 1863 ...
Data Summary - Daily Activity



head(daily_activity)
## Id ActivityDate TotalSteps TotalDistance TrackerDistance
## 1 1503960366 4/12/2016 13162 8.50 8.50
## 2 1503960366 4/13/2016 10735 6.97 6.97
## 3 1503960366 4/14/2016 10460 6.74 6.74
## 4 1503960366 4/15/2016 9762 6.28 6.28
## 5 1503960366 4/16/2016 12669 8.16 8.16
## 6 1503960366 4/17/2016 9705 6.48 6.48
## LoggedActivitiesDistance VeryActiveDistance ModeratelyActiveDistance
## 1 0 1.88 0.55
## 2 0 1.57 0.69
## 3 0 2.44 0.40
## 4 0 2.14 1.26
## 5 0 2.71 0.41
## 6 0 3.19 0.78
## LightActiveDistance SedentaryActiveDistance VeryActiveMinutes
## 1 6.06 0 25
## 2 4.71 0 21
## 3 3.91 0 30
## 4 2.83 0 29
## 5 5.04 0 36
## 6 2.51 0 38
## FairlyActiveMinutes LightlyActiveMinutes SedentaryMinutes Calories
## 1 13 328 728 1985
## 2 19 217 776 1797
## 3 11 181 1218 1776
## 4 34 209 726 1745
## 5 10 221 773 1863
## 6 20 164 539 1728
str(daily_sleep)
## 'data.frame': 413 obs. of 5 variables:
## $ Id : num 1.5e+09 1.5e+09 1.5e+09 1.5e+09 1.5e+09 ...
## $ SleepDay : chr "4/12/2016 12:00:00 AM" "4/13/2016 12:00:00 AM" "4/15/2016 12:00:00 AM" "4/16/2016 12:00:00 AM" ...
## $ TotalSleepRecords : int 1 2 1 2 1 1 1 1 1 1 ...
## $ TotalMinutesAsleep : int 327 384 412 340 700 304 360 325 361 430 ...
## $ TotalTimeInBed : int 346 407 442 367 712 320 377 364 384 449 ...
skim(daily_sleep)
Data Summary - Daily Sleep



head(daily_sleep)
## Id SleepDay TotalSleepRecords TotalMinutesAsleep
## 1 1503960366 4/12/2016 12:00:00 AM 1 327
## 2 1503960366 4/13/2016 12:00:00 AM 2 384
## 3 1503960366 4/15/2016 12:00:00 AM 1 412
## 4 1503960366 4/16/2016 12:00:00 AM 2 340
## 5 1503960366 4/17/2016 12:00:00 AM 1 700
## 6 1503960366 4/19/2016 12:00:00 AM 1 304
## TotalTimeInBed
## 1 346
## 2 407
## 3 442
## 4 367
## 5 712
## 6 320
str(weight_log)
## 'data.frame': 67 obs. of 8 variables:
## $ Id : num 1.50e+09 1.50e+09 1.93e+09 2.87e+09 2.87e+09 ...
## $ Date : chr "5/2/2016 11:59:59 PM" "5/3/2016 11:59:59 PM" "4/13/2016 1:08:52 AM" "4/21/2016 11:59:59 PM" ...
## $ WeightKg : num 52.6 52.6 133.5 56.7 57.3 ...
## $ WeightPounds : num 116 116 294 125 126 ...
## $ Fat : int 22 NA NA NA NA 25 NA NA NA NA ...
## $ BMI : num 22.6 22.6 47.5 21.5 21.7 ...
## $ IsManualReport: chr "True" "True" "False" "True" ...
## $ LogId : num 1.46e+12 1.46e+12 1.46e+12 1.46e+12 1.46e+12 ...
skim(weight_log)
Data Summary - Weight Log



head(weight_log)
## Id Date WeightKg WeightPounds Fat BMI
## 1 1503960366 5/2/2016 11:59:59 PM 52.6 115.9631 22 22.65
## 2 1503960366 5/3/2016 11:59:59 PM 52.6 115.9631 NA 22.65
## 3 1927972279 4/13/2016 1:08:52 AM 133.5 294.3171 NA 47.54
## 4 2873212765 4/21/2016 11:59:59 PM 56.7 125.0021 NA 21.45
## 5 2873212765 5/12/2016 11:59:59 PM 57.3 126.3249 NA 21.69
## 6 4319703577 4/17/2016 11:59:59 PM 72.4 159.6147 25 27.45
## IsManualReport LogId
## 1 True 1.462234e+12
## 2 True 1.462320e+12
## 3 False 1.460510e+12
## 4 True 1.461283e+12
## 5 True 1.463098e+12
## 6 True 1.460938e+12
After executing these commands, we can see the:
-
Number of records and columns
-
Data type of every columns
-
Number of null and non null values
Here we see that there are 940 records in daily_activity data, 413 in daily_sleep and 67 in weight_log. There are no null values present in any of the data set, So there is no requirement to clean the data. But the date column is in character format, so we need to convert it into datetime64 type. I have also created month and day of week column as we need them in analysis.
daily_activity$Rec_Date <- as.Date(daily_activity$ActivityDate,"%m/%d/%y")
daily_activity$month <- format(daily_activity$Rec_Date,"%B")
daily_activity$day_of_week <- format(daily_activity$Rec_Date,"%A")
We are also going to count the unique IDs to make sure whether the data has 30 IDs as claimed by the survey.
We can calculate by using the direct function.
n_distinct(daily_activity$Id)
[1] 33
We'll also use SQL Query to confirm the IDs
* distinct_id_1 <- sqldf("SELECT COUNT(DISTINCT(Id)) as dist_record FROM daily_activity")
* distinct_id_1
Upon calculation, we can see that there are 33 unique IDs instead of 30. It is possible that some users may have created additional IDs during the survey period.
04 Analyze Phase
Now we need to summarize the data. So that we can find comprehensive insights
daily_activity %>%
select(TotalSteps,TotalDistance,SedentaryMinutes,VeryActiveMinutes) %>%
summary()
## TotalSteps TotalDistance SedentaryMinutes VeryActiveMinutes
## Min. : 0 Min. : 0.000 Min. : 0.0 Min. : 0.00
## 1st Qu.: 3790 1st Qu.: 2.620 1st Qu.: 729.8 1st Qu.: 0.00
## Median : 7406 Median : 5.245 Median :1057.5 Median : 4.00
## Mean : 7638 Mean : 5.490 Mean : 991.2 Mean : 21.16
## 3rd Qu.:10727 3rd Qu.: 7.713 3rd Qu.:1229.5 3rd Qu.: 32.00
## Max. :36019 Max. :28.030 Max. :1440.0 Max. :210.00
weight_log %>% select(WeightKg,BMI) %>% summary()
## WeightKg BMI
## Min. : 52.60 Min. :21.45
## 1st Qu.: 61.40 1st Qu.:23.96
## Median : 62.50 Median :24.39
## Mean : 72.04 Mean :25.19
## 3rd Qu.: 85.05 3rd Qu.:25.56
## Max. :133.50 Max. :47.54
Interpreting statistical findings:
1.Findings from Daily Activity data :
-
The average count of recorded steps is 7638 which is less than the recommended 10000 steps. The average of total distance covered is 5.490 km which is also less than the recommended 8 km mark.
-
The average sedentary minutes is 991.2 minutes or 16.52 hours which is very high as it should be at most 7 hours. Even if you are doing enough physical activity, sitting for more than 7 to 10 hours a day is bad for your health. (source: HealthyWA article).
-
The average of very active minutes is 21.16 which is less than target of 30 minutes per day. (source:verywell fit)
2.Findings from weight log:
-
We can not conclude healthiness of person just by knowing their weight. There are other factors like height and fat percentage that could also affect health.
-
The average of BMI is 25.19 which is slightly grater than the healthy BMI range which is between 18 and 24.9.
3.Findings from daily sleep data:
To find insights from the sleep data, we need to run the following SQL queries:
Avg_minutes_asleep <- sqldf("SELECT SUM(TotalSleepRecords),SUM(TotalMinutesAsleep)/SUM(TotalSleepRecords) as avg_sleeptime
FROM daily_sleep")
Avg_minutes_asleep
## SUM(TotalSleepRecords) avg_sleeptime
## 1 462 374
Avg_TimeInBed <- sqldf("SELECT SUM(TotalTimeInBed)/SUM(TotalSleepRecords) as avg_timeInBed FROM daily_sleep")
Avg_TimeInBed
## avg_timeInBed
## 1 409
There is difference of 35 minutes between time in bed and sleep time that means it takes on an average 20 to 30 minutes to fall asleep for peoples.
We will also calculate number of distinct records in daily sleep and weight log data.
n_distinct(daily_sleep$Id)
[1] 24
n_distinct(daily_sleep$Id)
[1] 8
05 Share Phase
In this step, we'll create visualizations based on our analysis and keytakeaways.
daily_activity$day_of_week <- ordered(daily_activity$day_of_week,levels=c("Monday","Tuesday","Wednesday","Thursday","Friday",
"Saturday","Sunday"))
ggplot(data=daily_activity) + geom_bar(mapping = aes(x=day_of_week),fill="blue") + labs(x="Day of week",y="Count",title="No. of times users used tracker across week")

Judging by the bar chart, the usage frequency of the fitbit tracker app is high on Sunday, Monday, and Tuesday when compared to the rest of the weekdays.
This behavior could be related to how busy the users tend to be in the mid week due to the amount of pressure they receive from work. As a result, people become more active at around the start of each week.
Now let's take a look at the calories. I will create a visualization to highlight any correlations
mean_steps <- mean(daily_activity$TotalSteps)
mean_steps
[1] 7637.911
mean_calories <- mean(daily_activity$Calories)
mean_calories
[1] 2303.61
ggplot(data=daily_activity) + geom_point(mapping=aes(x=TotalSteps, y=Calories, color=Calories)) + geom_hline(mapping = aes(yintercept=mean_calories),color="yellow",lwd=1.0) +
geom_vline(mapping = aes(xintercept=mean_steps),color="red",lwd=1.0) +
geom_text(mapping = aes(x=10000,y=500,label="AverageSteps",srt=-90)) +
geom_text(mapping = aes(x=29000,y=2500,label="Average Calories")) +
labs(x="StepsTaken",y="Calories Burned",title = "Calories burned for every step taken")

Calories burned for every step taken
-
It is a positive correlation with some outliers at bottom and top of scatter plot.
-
It is clear from the plot that intensity of calories burned increase with number of steps taken.
ggplot(data=daily_activity, aes(x=TotalSteps, y=SedentaryMinutes, color = Calories)) +
geom_point() + geom_smooth(method = "loess",color="green") +
labs(x="Total Steps",y="Sedentary Minutes",title="Total Steps vs Sedentary Minutes")
`geom_smooth()` using formula 'y ~ x'

Total steps taken vs sedentary minutes
The steps taken are less than 10000. The relation between them is inverse, but as the number of steps increases past 10000, there is no drastic change in relation.
ggplot(data=daily_sleep, aes(x=TotalMinutesAsleep, y=TotalTimeInBed)) + geom_point() + stat_smooth(method = lm) +
labs(x="Total Minutes a sleep", y="Total Time in Bed", title = "Sleep Time vs Time in Bed")
`geom_smooth()` using formula 'y ~ x'
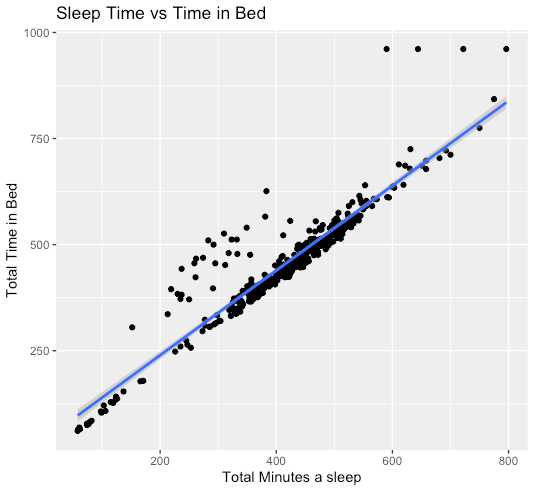
Relation between sleep and time in bed
Strong positive correlation between TotalTimeInBed and TotalMinutesAsleep. However, there are some outliers in this graph in the middle and at the top
ggplot(data=daily_activity,aes(x = VeryActiveMinutes, y = Calories, color = Calories)) + geom_point() + geom_smooth(method = "loess",color="orange") +
labs(x="Very Active Minutes",y="Calories",title = "Very Active Minutes vs Calories Burned")
`geom_smooth()` using formula 'y ~ x'

Relation between very active minutes and calories burned
As we can see, there is a high correlation between very active minutes and calories burned.
ggplot(data=daily_activity,aes(x=SedentaryMinutes,y=Calories,color=Calories)) +
geom_point() + geom_smooth(method="loess",color="red") +
labs(y="Calories", x="Sedentary Minutes", title="Calories vs. Sedentary Minutes")
`geom_smooth()` using formula 'y ~ x'

Relation between sedentary minutes and calories burned:
The data shows a positive correlation of up to 1000 sedentary minutes. The relation is inverse after 1000 sedentary minutes
activity_min <- sqldf("SELECT SUM(VeryActiveMinutes),SUM(FairlyActiveMinutes), SUM(LightlyActiveMinutes),SUM(SedentaryMinutes)
FROM daily_activity")
activity_min
## SUM(VeryActiveMinutes) SUM(FairlyActiveMinutes) SUM(LightlyActiveMinutes)
## 1 19895 12751 181244
## SUM(SedentaryMinutes)
## 1 931738
With these plot values, I will then create a 3D pie chart to show a comparison between the percentage of activity by minutes
x <- c(19895,12751,181244,931738)
x
piepercent <- round(100*x / sum(x), 1)
colors = c("red","blue","green","yellow")
pie3D(x,labels = paste0(piepercent,"%"),col=colors,main = "Percentage of Activity in Minutes")
legend("bottomright",c("VeryActiveMinutes","FairlyActiveMinutes","LightlyActiveMinutes","SedentaryMinutes"),cex=0.5,fill = colors)

Percentage of activity in Minutes:
• Based on this 3D pie chart, we can see that the percentage of sedentary minutes if very high compared to the other factors.
• Sedentary Minutes covers 81.3% of the pie chart which indicates that users are inactive for a longer period of time.
• The percentage of Fairly Active Minutes and Very Active are much lesser compared to other activities.
We will now use the daily activity data to calculate the sum of different distance values.
activity_dist <- sqldf("SELECT SUM(ModeratelyActiveDistance),
SUM(LightActiveDistance), SUM(VeryActiveDistance),SUM(SedentaryActiveDistance)
FROM daily_activity")
activity_dist
## SUM(ModeratelyActiveDistance) SUM(LightActiveDistance)
## 1 533.49 3140.37
## SUM(VeryActiveDistance) SUM(SedentaryActiveDistance)
## 1 1412.52 1.51
Based on the calculation, the values of the sedentary active distance is much less in comparison to the other distances.
I will create a 3D pie chart to show a visual comparison of the percentage of activity in minutes
y <- c(533.49,3140.37,1412.52)
y
piepercent <- round(100*y / sum(y), 1)
colors = c("orange","green","blue")
pie3D(y,labels = paste0(piepercent,"%"),col=colors,main = "Percentage of Activity in Distance")
legend("bottomright",c("ModeratelyActiveDistance","LightlyActiveDistance","VeryActiveDistance"),cex=0.5,fill = colors)

Percentage of activity in distance:
Based on the pie chart show:
• Lightly active distance has the highest percentage of 61.7% compared to moderately active distance which is 10.5%
• I noticed that very active distance has a percentage of 27.8% which isnt bad, but has potential to increase so that users can meet their fitness goals.
Next, we will calculate the number of users who are overweight. The CDC national public health agency states that the BMI for a healthy person is between 18.5 and 24.9. Users that have a BMI over 24.9 are considered overweight.
count_overweight <- sqldf("SELECT COUNT(DISTINCT(Id))
FROM weight_log WHERE BMI > 24.9")
count_overweight
## COUNT(DISTINCT(Id))
## 1 5
Now I will create a 3D pie chart once more to see the percentage comparison of healthy users and overweight users.
z <- c(5,3)
piepercent <- round(100*z / sum(z),1)
colors = c("red","green")
pie3D(z,labels=paste0(piepercent,"%"),explode=0.1,col=colors,radius=1,main="Percentage of people with Over Weight vs Healthy Weight")
legend("bottomright",c("OverWeight","HealthyWeight"),cex=0.5,fill=colors)

Based on the pie chart, there are more overweight users with 62.5% which is higher than healthy users with 37.6%.
Therefore, there is potential to increase the amount of users with healthier weight.
06
Act Phase
The goal of analysis is correct as we got many useful insights from the FitBit data,which will help us to make data driven decision making. Both companies develop similar kind of products.So,the common trends surrounding health and fitness can also be applied to Bellabeat customers.
Based on our analysis I have following recommendations:
-
We have analysed that most of the people use application to track the steps and calories burned;less number of people use it to track sleep and very few use it to track weight records.So, I will suggest to focus on step,calories and sleep tracking more in application.
-
People prefer to track their activities on sunday, monday and tuesday than other week days.I think this behaviour is because people get busier in week end days due to work pressure and they don’t get enough time to track their activity.That’s why people are more active on sunday and starting 2 days of week.
-
The relation between steps taken vs calories burned and very active minutes vs calories burned shows positive correlation.So, this can be a good marketing strategy.
-
Majority of users 81.3% who are using the FitBit app are inactive for longer period of time and not using it for tracking their health habits.So, this can be a great chance to use this information for market strategy as Bellabeat can alert people about their sedentary behaviour time to time either on application or on tracker itself .
-
Majority of the users 62.5% who are using fitness tracker are overweight.So, there is an opportunity to influence the people so that they can become healthier.
-
Bellabeat marketing team can encourage users by educating and equipping them with knowledge about fitness benefits, suggest different types of exercises, calories intake and burn rate information on Bellabeat application.